The Diamond Age é um livro de Neal Stephenson sobre nano-tecnologia, educação infantil e choque de culturas, e pode apostar que é uma das melhores coisas de se ler. A maior parte da história se passa em Xangai, mas não na China, já que ela, assim como todos os outros estados nacionais, não existe na época em que se passa a história, em seu lugar temos a corrupta “República Costeira” e o ancestral e confunciano “Reino Celestial”.
Na Era do Diamante, ou você faz parte de uma tribo, ou dificilmente morrerá de velhice. E uma tribo não é aquele bando de Emos andando em shopping centers e vestindo as mesmas roupas, a tribo do Reino Celestial corresponde a população da China Continental, por exemplo. Os laços tribais podem consistir em partilhar da mesma filosofia e visão de mundo, como os neo-Vitorianos, líderes em nanotech, ou ser afinidades genéticas e históricas, como os Nipponeses, número dois em nanotech.
A história começa com um lorde neo-Vitoriano, Alexander Chung-Sik Finkle-McGraw, encomendando a John Percival Hackworth, Artifex de sua Majestade Rainha Victoria II, um livro para educar sua neta, melhor do que seus filhos foram educados, algo com um toque subversivo. Não um livro comum, é claro, todos acessam informação via papéis eletrônicos (que se dobram sozinhos, graças às nano-máquinas), este livro, “A Cartilha Ilustrada da Jovem Dama”*, deveria contar uma história fictícia, porém baseada em todos os acontecimentos da vida da menina, ao mesmo tempo que ensina sobre os mais diversos campos de conhecimento: alfabetização, artes marciais, etiqueta, astronomia, cozinha, máquinas de turing e, claro, nanotecnologia. A cartilha é capaz de conhecer o ambiente e mesmo os processos biológicos de quem estiver ao redor usando nano-sondas e integrar esses dados nas histórias com sua pseudo-inteligência. (Aparentemente na Era do Diamante eles desistiram do termo inteligência artificial.)
Outra idéia empolgante (para programadores, pelo menos) é o Compilador de Matéria (M.C.), capaz de materializar qualquer coisa criada pelos engenheiros nanotecnológicos, de cavalos robôs a computadores, até mesmo cartilhas… O caso é que o senhor Hackworth faz uma cópia ilegal da invenção que foi contratado para desenvolver para sua própria filha. Contudo, todos os compiladores tiram a matéria de uma fonte central, que denunciaria sua cópia imediatamente, e ele provavelmente seria expulso da tribo. Ele então recorre ao Dr. X, um mandarin do Reino Celestial que possui um rústico compilador com fonte própria. Na volta pra casa é atacado por uma gangue, a mando do Dr. X, que tinha interesse próprios na cartilha e no próprio Sr. Hackworth. Não reconhecendo o livro como um objeto de valor a gangue não percebe quando um dos membro guarda a cartilha.
Harv, dá a Cartilha a Nell, sua irmã de quatro anos, que passa a maior parte do tempo conversando com o livro, ouvindo suas histórias e aprendendo. No tempo restante ela e Harv são ignorados pela mãe e espancados pela sucessão de namorados truculentos.
No de correr da trama são levantadas questões sobre a superioridade de uma cultura sobre as outras, o que realmente funciona na educação de crianças, e como conhecimento e instrução podem mudar a vida de uma pessoa, embora em um dado momento a protagonista se veja numa situação onde a filiação a um grupo social teria sido sua melhor chance de segurança.
Para minha profunda felicidade e indescritível (e sua também, pode acreditar) fiquei sabendo que o SciFi Channel vai filmar The Diamond Age como série de 6 horas, com produção de George Clooney e roteiro do próprio Neal Stephenson, o que me deixa curioso, pois embora seus dialógos sejam muito bons, partes extensas do livro sejam descritivas, mas provavelmente várias páginas se tornarão cenas de 10 segundos.
Por que Era do Diamante, você pergunta? Ora, porque as Eras históricas costumam ser definidas pelos materiais que a raça humana é capaz de manipular. No começo do livro alguns personagens estão voando sobre o mar num luxuoso avião com chão de diamante, o mesmo diamante que qualquer pessoa poderia produzir nos compiladores de matéria caseiros que todos possuem.
Seek The Alchemist!
* Minha livre tradução para “The Young Lady Illustrated Primer”.





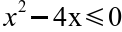
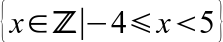
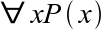
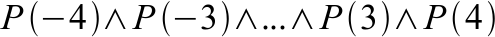
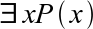

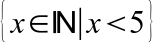

{kind=link}