Version 1.0 – Jul 7th, 2011
by Marcelo Lira dos Santos
<setanta that may be found at gmail dot com>
Binding C++ to dynamic high level languages is a complex business, full of details that if not properly handled will result in failed bindings that will provide you with plenty of headaches. I decided to write down all the issues that the PySide team had to deal with in the process of developing the Python bindings for the Qt library, together with the binding generator Shiboken. It was a long walk from the starting point where we thought that C++ bindings would be something like “C bindings with classes” to the problems explained here.
The topics that follow will expose each problem as generically as possible, in a way that “Python” may be replaced by “Your Favorite High Level Language”. Each topic has a section called Solution explaining how we solved the problem in Shiboken/PySide; things get more specific here, but can serve as real life examples that will help other binding developers.
Before getting started I want to stress the importance of agreeing in the terminology used. I’m not saying you should agree with the terminology seen here, but that the team working in a binding project must known what each other is talking about. Some ideas are repeated or stressed in the text because they were the center of long and tiresome discussions, which many times ended with the understanding that each one was talking about a different thing. I hope the explanations in the text are clear enough, but as Mortimer Adler explained to me words can have many meanings, but terms must be univocal, thus for safety’s sake I’ve put the definition of some important terms in the end.
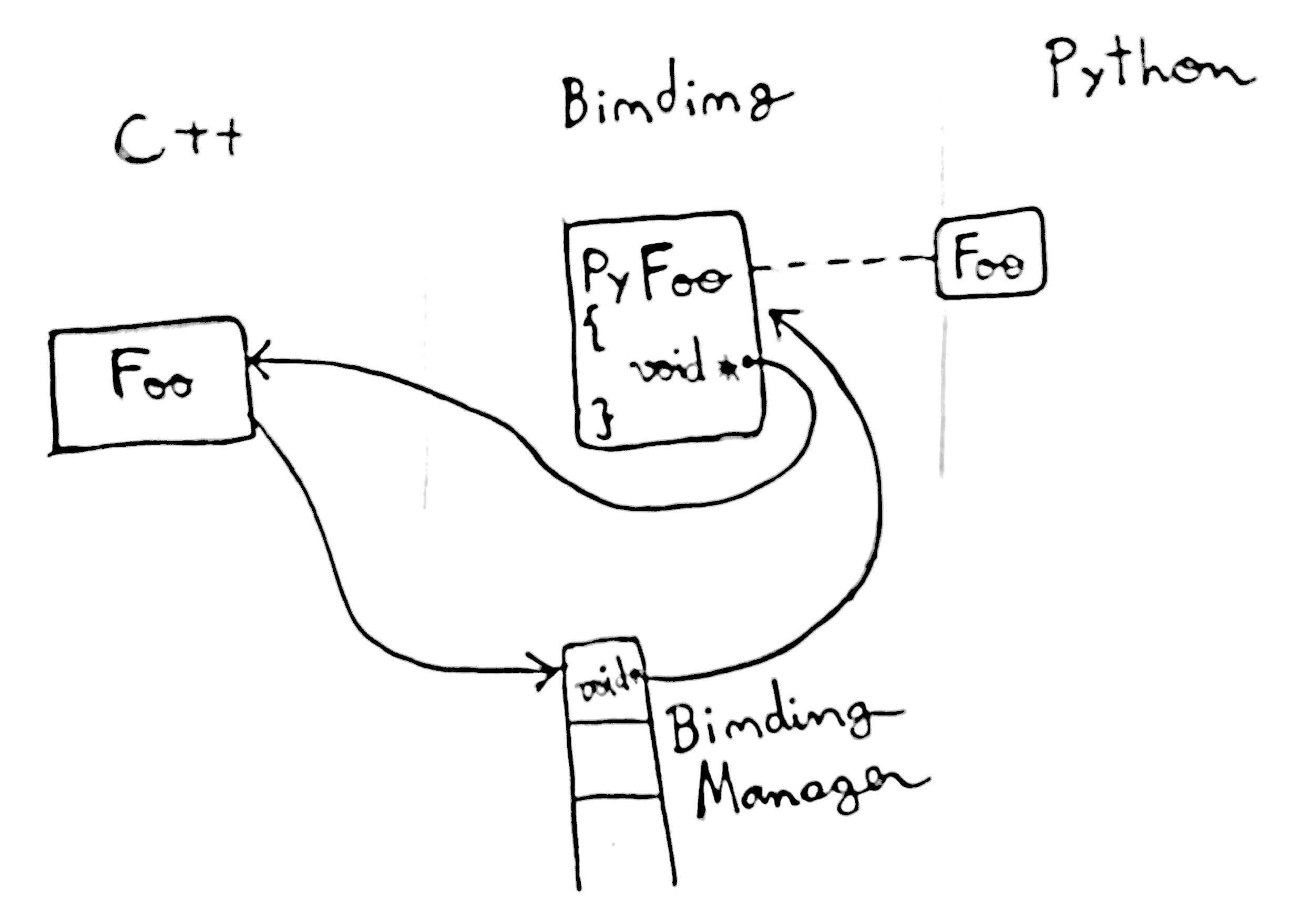
§ 1. Associating C++ objects with Python objects
This is the most basic need of a binding: to associate the C++ object with the Python object that represents it, we call the latter “wrapper” for obvious reasons. When the Python programmer instantiates an object for one of the classes in the binding module, both the Python object and a C++ object are created, and when the Python object is deleted, it must delete the C++ object as well.
Solution
We use a component called Binding Manager to keep the C++/Python object association; It is part of the supporting library libshiboken, and boils down to a hash table with the memory address of C++ objects as keys, and Python wrapper objects as values – this is needed, for example, when a call from Python to C++ returns an object and the binding must find out which Python object was originally wrapping it. In the opposing direction, the C data struct of the Python wrappers contains pointers to the C++ objects.
§ 2. Type Conversions
Whenever a C++ method is called from Python its arguments must be converted from Python to C++, and from C++ to Python for its result. Let’s be more precise with a “typology of types”, which is:
Primitive
Simple C++ types like integer, float and boolean have a correspondent in Python, so Python wrappers for them wouldn’t make any sense, just straight conversion using CPython functions like PyFloat_AsDouble or PyFloat_FromDouble. It may happen that some C++ classes must be turned into Python primitives; this would be the case with a C++ class representing complex numbers, for Python already has such a type, and the binding developer would have to provide a way to convert such types in both ways.
Container
C++ templates designed to contain some other types like a std::list<int>. It is in the best interest of the binding developer that the conversion of a container be as generic as a template is, so you can define the conversion procedures for the std::list and do not mind about the type it contains, for it was already taken care elsewhere.
Value
These types, that could be also called scalars, are meant to be copied when passed as arguments or returned as results in C++. In the same fashion when a Python wrapper of this object is passed by value to a C++ function, it’s not the same object that is passed, as a Python programmer would expect, but a copy, as C++ wants.
Mind that there may be a C++ function that receives a pointer to a value type, in that case, the object passed to C++ will be the same held by the Python wrapper. The same thing with references which are, roughly speaking, sugar coating for pointers.
Object
A C++ object type is one designed to be passed around only as a pointer, usually with their copy constructor and operator defined as private. These are the closest to what a Python programmer should expect their objects to behave.
Solution
In Shiboken we adopted a type conversion solution based on C++ templates, so we may compose converters for containers with other types. It was inspired by v8-juice, the C++ toolkit for extending Google’s v8 JavaScript engine.
In Shiboken bindings you can define Converter<SOMECLASS> and Converter<std::list>, and Shiboken will be able to do Converter<std::list<SOMECLASS> >. There is also a set of basic converters in libshiboken.
Two limitations of this method is that the converters of a module must be made available to others extending on it. For example: QtCore will have its converters defined for QObject, and QtGui will have methods that receive QObjects and will need the template containers defined by QtCore. Also, GCC is not fond of templates, and generates big binaries when they’re involved.
§ 3. Implicit Type Conversions
C++ has a very evil feature called implicit conversion: if your class has a constructor that receives a single argument of, say, type A, any place that accepts your class will also accept a variable of type A, and C++ will kindly and silently use it to create a new instance of your class. Ok, it doesn’t sound that evil, and I’m talking from the biased perspective of a binding developer.
The evilest part are the cast operators! With them the C++ programmer can tell the compiler that any type is convertible to other and how to do it, so that any function that accepts the output type of the cast operator will also accept the conversion input type. Furthermore, these cast operators can be defined outside the library where the output type is found. In other words, analyzing a library you may know which implicit conversions there are, but you can’t predict which ones will appear.
Let’s use see a C++ code snippet to help clarify this point.
class A {
A(int);
}
void function(A);
The mechanism of implicit conversion will cause function to accept instances of A and also instances of int. Then later, we add:
operator A(const B&) { ... }
From now on, function will also accept instances of B as argument. Thankfully, these conversions are 1 level deep, i.e. there’s no transitivity: A converts to B, but B converting to C doesn’t imply that A converts to C.
The importance of implicit conversions will be made clear in § 4.
§ 4. Method/Function Overloading
In C++ one can have multiple functions or methods with the same name, but different argument types; the combination of name and argument types is called the method’s “signature”. Since Python doesn’t have this feature, there will be only one method for each set of C++ overloads.
In C++ the compiler will decide which method to call based on the statically defined types of the arguments given in the call, but in Python you will know what the programmer wants only at runtime, so in every call to wrapped C++ functions or methods the types must be checked to decide which C++ overloaded method the binding should call, or if a type error exception should be raised.

Pay attention to one very important point: even though you can’t tell which types the user will throw in a method call, at least you will know before the Python module compilation all the possible types from the list of declared method signatures. So, the type checking is made at runtime, but which to check is decided before the binding compilation.
§ 4.1. Mind The Implicit Conversions
The C++ implicit conversions have a major role complicating things for the overload decision process. This is better explained with an example:
class Foo {
Foo(int);
};
class Bar {};
void function(Foo);
void function(Bar);
The Python binding for the function "function" must check the argument passed from Python to see if function(Foo) or function(Bar) should be called; but, function(int) is also an acceptable call. In practice, this causes the binding to ask if the argument passed is convertible to each of the expected types, instead of asking if it is exactly one of the expected types.
Perhaps it doesn’t sound as complicated as it really is. It’s not uncommon to find a set of function overloads with a type that is there both explicitly in a function signature, but also as an implicit conversion to a type present in other of the function signatures. To exemplify, suppose there is a declared void function(int) in the previous example. If in the process of deciding which method to call, you ask first if int is convertible to Foo, and later you ask if int is convertible to int, the Foo signature will always be called and the int one will never be reached.
And don’t forget another complicating factor: cast operators (as mentioned in § 3) that could be defined in a library that extends on the one being wrapped. The scheme checking if a type is convertible to another must be extensible by modules imported after the one that contains the extended type. Again, an example should clarify this: suppose you have libone that defines type A and function that accepts it as argument, there is also libtwo that defines type B and a cast operator that takes B and turns it into A. Now, you make Python bindings for those libraries: bindingone and bindingtwo. In a Python code that imports bindingone, calling a function that gets a type A object is correct, but if the user also imports bindingtwo calling a function that expects a type A must accept a type B object as well.
IMPORTANT! There’s a subtlety in this. Although this change is considered to happen at run time (i.e. at the moment the second binding is imported), it is known when the binding for the second library is generated. In other words: it is completely predictable for the binding developer. A simple point of for extension for the converter, where the second binding that extends the first could register the new conversion should suffice.
May your patience allow me to reinforce the last point using the negative. Since there’s nothing the Python developer, the one who uses the bindings, could do to interfere with the C++ types and their convertibility, this kind of run time change should be discarded as impossible.
§ 4.2. Argument With Default Values
In C++ even a method with a single signature can behave as having multiple overloads. That’s possible with default argument values. For example, with this definition void function(int a = 0, bool b = false), function could be called in 3 different ways: function(), function(1) and function(1, true). From the Python perspective it makes most sense to turn those C++ arguments with default values in Python named arguments with default values, so the user will be able make a call like function(b=true), and expect the value of a to be filled with the default value 0.
Solution
Shiboken deals with the overload decision problem analyzing a set of method overloads and organizing the argument types in a decision graph as seen in the picture below:

There are 4 method overloads, and the first argument in all of them is an A. Binding code generated with Shiboken will ask first how many arguments the user wants to send to the underlying C++ method, if less the minimal accepted by any of the overloads, then throw an error. Secondly, check if the first argument passed is an integer, or something convertible to it, if not throw an error. And so on, until we find the correct C++ overload signature to call. Notice that this argument by argument approach avoids the delay of checking all the types of each entire signature at a time, until finding the right one.

The order in which the argument types are checked to decide which C++ overload to call, is defined using a topologically sorted graph built to express which types are convertible from other types. The types with less implicit conversions are checked first – more specifically if there is type A and type B, and the second can be built from A, A gains precedence over B, thus it is checked first.
The Shiboken Converters mentioned by the solution on § 2, besides the Python/C++/Python type conversion, also provide the isConvertible information, to check if a Python object is acceptable as argument for a given C++ argument type. With information about both set of method overloads and the implicit conversions of all the involved types, the types of all arguments in the overloads are checked in the proper order so that all possibilities of call are reachable.
Certainly other approaches may be used, but any solution for this should take into account the following factors:
- The correct method to call will be decided from a defined known set of overloads, using the arguments provided by the Python code.
- Implicit type conversion must be taken into account when deciding which overload to call.
- Implicit type conversion can be extended later by other bindings for libraries that define new cast operators (remember that the extending bindings will go through the same generation process of the bindings being extended).
As a last comment on this topic, I want to point out that three are the places where the sorting of a set of method overloads can be done to make the decision as fast as possible:
- During generation time.
- At the moment the binding is imported.
- At every single method call.
It’s obvious that the third option has the worse performance of all (and it can’t be cached, since you can’t know with which arguments Python will call the method next). The second is a reasonable option, but if you can have it all figured out at generation time (i.e., before compilation of the binding), why spend time organizing all the overloads for all methods in a library every time the user imports the bindings for it? Specially because no matter if the user imports the library ten thousand times, the process will be the same. But even though the first case is the best, in practice Shiboken does a combination of the generation time and Python module importing time: the bigger fixed part is a sequence of “if”s checking the types passed, and the smaller part of extending conversions with cast operators from other modules done when those modules are imported.
§ 5. Inheritance
The C++ classes exported to Python by the binding must enable the Python programmer to create classes that inherit from them. Superficially this is automatically enabled by the mere fact of the wrappers being Python types, but the underlying implementation of the Python wrapper will need additional information, hidden from the Python programmer, that must be available to inheriting classes created on Python.
Solution
In our implementation libshiboken provides a Python type called BaseWrapper from which all wrapped types derive, in the CPython it is represented by a structure that holds many data relevant to the proper binding operation. When any wrapped type is subclassed in Python, in practice a new structure of the same kind is created for the new type, and the relevant data must be copied to it from the parent type. That is done with a meta type that the Python interpreter will call whenever an user defined class inherits from a wrapped class, the meta type will create the new type and copy the relevant information from the parent struct to the inheriting one. Mind that we are copying information from a C struct to another because this is the CPython representation, in C, without any inheritance mechanisms.
§ 6. Virtual method overrides
Firstly, I’ll assume you know how C++ virtual methods work, and secondly, virtual methods are the main reason C++ bindings differ from C bindings. Consider the case where the Python programmer created a class that inherits from one found in the binding module, one that wraps a C++ class called Base with a virtual method called virtualMethod. Suppose that in C++ you have a function that receives a Base object and calls it’s virtualMethod, if I create a class Derived in Python that inherits from the wrapped class Base, and override the virtualMethod, the said C++ functions (exported to Python), must not only accept an instance of Derived, but also correctly call my Python override of virtualMethod. This is usually expressed as “C++ calling Python.
Solution
In Shiboken, besides generating Python wrappers, which are Python types defined in CPython that hold the underlying C++ objects, it also generates what we use to call C++ wrappers – C++ classes that inherit from all the C++ classes with virtual methods from the library being wrapped. The C++ wrappers override every virtual method found in C++, and the implementation looks for a Python override (with help of libshiboken), and if found calling it; otherwise the original C++ implementation is called – except if it is a pure abstract method, in that case a NotImplemented error is thrown.

When the library C++ calls the C++ wrapper virtual method, care is taken (by the code generator) to avoid calling itself again and again. When discovered that Python doesn’t override the virtual, the C++ wrapper explicitly calls the original C++ version of the virtual method.
The virtual method mechanism is what prevents using simple reflection to call C++ functions from Python. C++ wrappers with overrides for all virtual methods will always be needed. The KDE bindings have an interesting approach using Smoke, which separates the C++ wrapper code from the high level language binding code. Smoke creates a library containing C++ wrappers for all classes found in the library being wrapped, and through a standard API allows bindings for specific a language to instantiate C++ wrapper classes, put hooks on virtual methods to be notified when they’re called, etc. This results in better memory footprint when you have bindings of the same C++ library for multiple high level languages used in the same environment, at the cost of not having everything in a single pack.
§ 7. Protected Methods and Members
Protected methods or members in a C++ class behave as public for classes inheriting from it, and as private for everyone else. Since Python (and, I suppose, most similar high level languages) doesn’t have protected (or even private for that matter), in order to Python classes inheriting from wrapped classes to have access to protected members, the latter must be turned public.
Solution
When the generated binding is compiled with GCC, Shiboken uses the infamous “protected-public” hack, which is simply a line "#define protected public" e every header where a C++ wrapper is declared. This causes GCC to treat protected declarations as public declarations. That’s may seem strange, but save a lot of space. In other compilers one has to make C++ wrappers with public accessor methods for all classes containing protected members, even if they don’t have virtual methods.
§ 8. Multiple inheritance and casting pointers
As explained in § 1, there is a Binding Manager that relates C++ objects, identified by their memory addresses, to Python wrappers. Let’s complicate the scenario. Suppose there are two C++ classes, A and B, and a third C++ class C, that inherits from A and B. C can be passed as argument to any function that accepts A or B. Well, the memory layout for C will be the one used by A, followed by the one for B (in fact the layout could be different, but bear with me for now). Imagine now that the Python wrapper for C was passed to C++, and at some point C++ will call back Python via a virtual method that accepts a B object. C++ will pass the memory address of the Bpart of C, which will have a different memory address than it’s registered. The ascii illustration will help to visualize:

The binding must be able to relate the various different memory address to a single object that multiple inherits from others. In fact, this must be done cumulatively for all his tree of ancestor types, since it could be cast for any of them.
Solution
When C++ passes a memory address of a C++ object to Python, the libshiboken’s Binding Manager will use the address to recover the related Python wrapper, so when registering a Python wrapper in the manager, all the possible memory addresses of the underlying C++ object are used as keys pointing to the same Python wrapper.
Shiboken generator acquire the possible memory addresses using a combination of C++ casts. For the example of class Derived : public Base1, public Base2, we would have:
const Derived* ptr = OBJECT COMES FROM SOMEWHERE...; size_t base = (size_t) ptr; ((size_t) static_cast(ptr)) - base ((size_t) static_cast((Derived*)((void*)ptr))) - base ((size_t) static_cast(ptr)) - base ((size_t) static_cast((Derived*)((void*)ptr))) - base
The code above is obviously altered from the real one, that’s just to give an idea. Every time an instance of the Python wrapper is created, the calculated addresses are registers in association with it.
§ 9. Multiple inheritance of C++ classes in Python
Similarly to C++, Python supports multiple inheritance, so it is natural that a Python programmer would try to create a class inheriting from two or more that he found in the bindings he is using. As seen in § 8, multiple inheritance in C++ causes the memory representations of the new class and its ancestors to be mashed up. Who does that is the C++ compiler, which a Python class will not invoke. Thus, to enable the Python programmer to multiple inherit from C++ classes, there must be a binding mechanism to keep multiple C++ objects for a single Python class.
Solution
The struct representing the BaseWrapper in the Shiboken bingins instead of pointing to a single C++ object, it points to an array of them. And the generator outputs code that will use the correct object depending on the inherited method being called.
§ 10. Object Life Cycle
The life cycle of objects must be carefully managed by the binding. Mysterious segmentation faults could happen because of some mistake related to keeping track of the life and death of objects, and by “objects” I refer to the C++ object and also to its Python counterpart. All this is strongly related to Python reference counting and garbage collection.
§ 10.1. The Concept of Ownership
Ownership tells who, Python or C++, is responsible for deleting an object. When it’s Python’s turn to take the trash out, then if the reference count of a Python wrapper object reaches zero and it must die, the binding is responsible for deleting the underlying C++ object.
In the library being wrapped there could be some C++ functions that “steal” the ownership of an object passed as argument to it, that means that the said object will be used in the depths of C++ to be disposed later, at an unpredictable time, by C++ itself. When the Python wrapper reaches reference count zero and is about to be destroyed, it should not try to delete the C++ object that it points to, or else a double free error will happen.
Some times C++ creates a new object and gives it to Python, as is the case with factory functions. There’s no way to tell that a method is a factory analyzing the C++ syntax, so the binding developer must tell the binding that Python have the ownership of objects returned by such and such.
In fact all these possibilities can’t be deduced from the C++ headers analyzed by a generation tool, those situations of transference of ownership are given in the semantics of the C++ library methods and functions.
There must be a way to tell the binding when the ownership of an object must be given to C++ or Python.
§ 10.2. Parenting
When an object is said to be the parent of a second child object, that means it holds a reference to the child and will keep it alive while it is alive, and destroy the child object when it gets destroyed. Again, it’s not a feature of C++ that can be deduced from the syntax, but a design that a C++ library may implement. It is a special case of ownership, and it is better because in a simple transfering of object ownership to C++, we can’t tell when the transfered object will be destroyed, but with parenting as long as the parent is alive the children are assured to be alive too.
§ 10.3. C++ Keeping References to Python Owned Objects
There’s another case (yes, another one) where a C++ object keeps a reference to other object without taking responsibility (i.e. ownership) for it. One good example of this is the Model-View relationship.
I’ll introduce the problem with a simple example in pure Python:
class View(object):
def __init__(self, model):
self.model = model
def createViewAndModel():
model = Model()
return View(model)
view = createViewAndModel()
In the above code, you can see that the line self.model = model will increase the reference count of the model object and keep it alive while the view object is, even though the model object gets its reference counting decreased at the end of createViewAndModel.
Now suppose that Model and View are C++ classes exported to Python in some binding.
def createViewAndModel():
model = Model()
view = View()
view.setModel(model)
return view
view = createViewAndModel()
view2 = View()
view2.setModel(view.model())
In the code above the method View.setModel(model) will take the Python model object, and pass its underlying C++ object to the original C++ method View::setModel(Model*). The binding sees this method call as any other method call, it doesn’t know if it will hold a reference to the model object, or just look at it, or print something to stdout, thus the reference count of the C++ object’s Python wrapper will not be increased. At the end of the createViewAndModel function, the model object will have its reference count decreased and will be destroyed, but before that it will delete the underlying C++ object, that will still be used by the view in C++. This can be solved telling the binding to transfer the ownership of the model to C++, because the view C++ object can’t be expected to delete the object, after all it’s also being used by view2. So, there must be a way to inform the binding that some methods increase reference count of some or all of its arguments, and also decrease when removed from the view.
§ 10.4. C++ Wrappers and Life Cycle
The C++ wrapper is a handy tool to help in the management of an object life cycle; its C++ destructor method may be used to inform the binding about its death. With that last information, let’s review the possible scenarios.
Object created in Python
The underlying object of the Python wrapper is a C++ wrapper, if its ownership is transfered to C++ and happen to be destroyed there, the binding will be warned and the Python wrapper should not be deleted, for it’s reference count will not be zero at the time, but marked as containing an invalid C++ object. A Python wrapper marked this way should raise an error whenever any of it’s methods is called from Python.
Object created in C++
The C++ library will create objects from the original classes it has defined, and not our C++ wrappers, thus their destructors will not warn the binding about their deaths. So, if Python has a wrapper for an object created in C++ and pass it to a function that transfers the ownership to C++, the said wrapper must be marked as invalid on the spot. This is so because there’s no way to tell if the underlying C++ object will be destroyed right now, later or never, and since there is no C++ wrapper destructor to warn us about its death, the only safe way is to mark the Python wrapper for it as dangerous.
Solution
All the life cycle issues must be solved carefully, always with input from the binding developer, i.e. this can’t be automated. Shiboken has two main inputs from where it generates the binding code: the C++ headers of the library being wrapped, and a XML file describing how the elements found in the library should be exposed to Python. We call the XML the type system description, and it is expressive enough for the binding developer to tell which arguments of which functions transfer ownership from Python to C++ and vice-versa. Through it is also possible to tell who is parenting who, and who is keeping or releasing a reference for an object.
All this semantic information about the binding translates to code as flags in the C structs that represent Python wrappers in CPython. Flags such as “invalid Python wrapper”, “ownership of this object is with Python or C++”, “underlying C++ object created in C++”. There is also a list of referred objects to manage the reference counting.
§ 11. Identifying Precisely The Type of an Object Generated in C++
Sometimes C++ creates an object of a given type but gives it to Python as if it were of another type, which causes the binding to create a Python wrapper that represents the C++ object imprecisely. Let’s use an example:
class Base {};
class Derived : public Base {};
Base* createDerived();
When the Python programmer calls the function createDerived, he’ll get a brand new Derived but the binding will think it is a Base object, thus it will create the corresponding Base Python wrapper. Clearly the Python developer is left wanting with this imprecise representation of the value returned from C++. There isn’t a perfect solution for this problem, but a couple of things may help.
§ 11.1. Inheritance and Internal Library Classes
It can get worse, though. Suppose there is another class, it inherits from Derived but is internal, i.e. not made externally visible by the library for which we want to make a binding.
class Internal : public Derived {};
Base* createSomething() {
if (blah)
return new Derived();
else if (bleh)
return new Internal();
return new Base();
}
Even if we can identify that the result is in fact an instance of Internal, we can’t make a Python wrapper of it, since it is unknown outside the C++ library. The binding need to go back in the class inheritance tree and find out which is the nearest exported class, and create a Python wrapper for this type and then stuff it with the Internal instance.
Solution
That is in fact a rough problem and, as said before, not always solvable. But we can try a couple of reasonable workarounds. (In fact, the idea of bindings is a “reasonable workaround” itself.)
The first workaround is simpler because the C++ library being wrapped already gives us a hand. There could be a class hierarchy in which each member identifies itself with a enum value. Example:
class Base {
enum Type {
BaseType,
DerivedType
};
virtual Type type() { return BaseType; }
};
class Derived : public Base {
virtual Type type() { return Base::DerivedType; }
};
And the internal class
class Internal : public Derived {};
Using the type() method of an object return by the previously seen createSomething() method the binding can correctly choose a Derived Python wrapper for the Internal instance, instead of using a Base Python type. Shiboken knows how to check for this with an attribute called polymorphic-id-expression in the type system XML entry for the Base and Derived types:
<object-type name="Base" polymorphic-id-expression="%1->type() == Base::BaseType"/>; <object-type name="Derived" polymorphic-id-expression="%1->type() == Base::DerivedType"/>;
Let’s break down all this voodoo. First, the value of polymorphic-id-expression will be used in a type discovery function that is part of the generated binding. Secondly, the mysterious %1 will be replaced the variable that holds the C++ object to be checked by the discovery function; %1 is what we call in Shiboken lingo a type system variable.
When the C++ library developers weren’t kind enough to provide hints to discover an object type, as we have seen previously, we can resort to use RTTI. The problem with this approach is that when you ask RTTI for the type of an instance of Internal it will answer that it is an instance of Internal, instead of the type of its nearest usable ancestor, like happens with polymorphic-id-expression. So, the binding will have to go through all the class hierarchy, in our example starting with Base and going down until we find Internal, and from there going up until we find the first ancestor class usable by the binding.
§ 12. Multiple Dependent Binding Modules
Wrapper types defined in one binding module must be available for other binding modules extending on the first. Using Qt as an example, you have QtCore library with its types, and QtGui library with many types that inherit from those in QtCore. In that case, the Python wrapper types in the QtCore bindings must be made available to the QtGui bindings, not only for the user at the Python level, but at binding level (be it CPython or whatever) so that the data structure representing an inheriting type can refer to its ancestor from the other binding module.
Solution
In Shiboken we have to share 2 kinds of files among binding modules:
The Module’s Generated Header
Shiboken generates a main header for each module containing type converters and template functions and numerical indexes used to export the Python types for each C++ type. The module initializer of a extending module (e.g. what QtGui is for QtCore) will retrieve the Python type objects using CObjects (they’re deprecated for Python 2.7, but PySide must support early versions of Python) and the indexes indicated in the extended module header.
Notice that although there is a header for the binding module, this doesn’t imply that an extending binding have to link against the first. Python extension modules should not link with each other. The generated module header contains only templates that cause the C++ compiler to generate code for each module that uses them.
Type System XML Files
The type system description tells Shiboken how the C++ library should be exported and modified to fit in Python, this file will be used by any other binding module extending on the first. It works the same way as include files in C and C++.
§ 13. Tweaks and Custom Code
It would be great if all the binding code could be generated with the merging of data from the headers of the target library, and semantic information from the type system description. But in real life there’s plenty of code that must be tackled in an individual basis. For example, when a C++ function accepts an array of integers in this form: function(int* array, int size). Is it really an array or a pointer to one integer? the second argument is the array’s size or some other thing? May be you can tell, but no binding generator can without the binding developer help.
Another example is the use of arguments to return the status of an operation.
bool ok; result = function(123, &ok);
In this case the ok variable is used to check if function succeeded of not in whatever it should do. To make it more Pythonic, the binding developer must be able to change function into this:
result, ok = function(123)
Let’s get back to the array example:
void function(int argc, char** argv);
The arguments for the function above is clearly (for us, humans) a list of strings, to Pythonize it properly it should be turned in something like this:
function(['one', 'two', 'three'])
The cases are endless, so I’ll stop here. The point is that the binding generation tool must provide means for the developer to tweak and fine tune the generated code. He must be able to add chunks of code, and must be able to identify where the custom code should be placed. He must be also able to remove and remove or change function arguments, interfere with the return type, rename functions, and so on.
Solution
The type system XML used to guide the binding generation is expressive enough to enable the developer to do all tweaking he needs to make the wrapped library suitable for Python. Mind that with great control comes great responsibility – you can really screw thing up. Certainly it would be perfectly possible to have XML tags in the type system to inform, say, “this functions arguments are in fact a list of TYPE”, but there must be a balance. Really common cases in the binding process should be done in a standard way, so that any fixes and improvements will affect every code generated. On the other hand, less common changes must be made with a series of changes, i.e. renaming, removing, replacing types, writing custom code. That said, remember that the less custom code the better, custom code has little semantic information, they’re a binary blob to be inserted blindly by the binding generator. The more semantic information the better decisions could be made by the generator.
Wrap Up
I may be forgetting some point that the time and repetition have made seem trivial and unnoteworthy, but I hope almost everything that one have to deal with when binding C++ to a dynamic high level language was included here. Otherwise, tell me and an upgraded version will follow.
Binding Generator Toolchain
That’s explained elsewhere (look for Shiboken in the Resources section at the end), but I think a brief explanation of the generator toolchain used by PySide can help.

The drawing above shows the three components of the generator toolchain, its input and output. The input was discussed before in the solution on § 12, and the output is obviously C++ code using CPython. APIExtractor is a library that parses C++ headers and the type system XML description of the binding, merges this information and delivers to whoever asks; it doesn’t need to be a binding generator. Generator Runner is a binary executable that links to APIExtractor and loads dynamically “generator modules”; again they don’t have to be really binding generators, they could draw a graph, generate documentation instead of code, etc. Shiboken is a dynamic module that is loaded and ran by Generator Runner, and is outputs the C++/CPython binding source code to be compiled into a Python extension module.
PySide’s binding toolchain derives from QtScriptGenerator, which in turn is a fork of Qt Jambi Generator. Both of them are monolithic applications, as was our first generator that produced source code that used Boost.Python. We discovered that Boost.Python has a terrible memory footprint problem (we were aiming at mobile) for it’s heavy use of C++ templates (in GCC compiler it gets really bad). The use of “templates inside templates inside templates” also made the code very complex to read and it was hard to introduce modifications in Boost.Python itself. But hey, it worked. So, to avoid dropping everything and starting from scratch, we separated the code of what is APIExtractor from the code generation part, and when a CPython replacement was ready, the Boost.Python generator front end was dropped.
The bottom line is: if you’re interested in creating a C++ binding generator for your favorite high level language, you can have a good head start using PySide’s tool chain. Everything is written in C++ and uses the QtCore library, but the generated code doesn’t have to be, as it happens with Shiboken. And if you prefer to write your generator in, say, Python, instead of C++, a bold project would be to create bindings for APIExtractor itself.
I would like to stress the importance of a binding generator when dealing with huge C++ libraries with hundreds of classes. If using some kind of binding language, like sip, or using a binding library, like Boost.Python, you’ll have to write so much repetitive code that your eyes and fingers will bleed. Even though PyQt, for example, is written in sip, it is maintained with an internal generator tool called metasip.
Clearly, there must be some human written input to guide the generation process, and it’s unavoidable that it will be proportional to the size of the wrapped C++ library. PySide has huge type system XML description files. Fortunately, the PySide project inherited the XMLs from QtScriptGenerator and Qt Jambi, that were modified to fit Python. One way to lighten the work of writing type system files for bindings of new libraries would be to improve APIExtractor to, given some library headers it would generate some initial type system, that would be changed by the user when needed.
Terminology
It’ll not be in alphabetical order.
User
In this case, user refers to the Python developer that imports and programs with the bindings.
Developer
The binding developer – PySide team and potentially you.
Python wrapper
The Python object that represents, or wraps, a C++ object. All C++ class found on the library, and not marked for exclusion by the binding developer, has a correspondent class in Python.
C++ wrapper
Between the original C++ classes found in the library being wrapped, and the Python wrappers that will be seen by the Python programmer, there must be C++ classes that override all virtual methods in all C++ classes exported to Python, so that virtual calls from C++ can be intercepted and send to Python.
Module
In Shiboken’s case is the Python extension module, an .so on Linux, .dll on Win32 or a .dylib on MacOS X.
Generation time
It’s what happen before binding compilation, and evidently way before run time. Decisions about the binding behavior should be done at this stage, to avoid imposing performance penalties for predictable repeating tasks at run time. Of course, sometimes such decisions could imply a bigger memory footprint, but not always.
User run time
What happens when each Python line of user’s code is executed. This is completely unpredictable, but its effects on binding behavior are limited.
Developer run time
When a new binding module is imported it may interfere with previously loaded modules. That’s a run time change, but with a difference. Although the incoming module is less limited on the depth of the changes it causes, such changes are predictable, because they happen inside what’s allowed by the binding framework.
Resources
- APIExtractor, Shi–bo–ken and PySide documentation
- The Qt Jambi Generator
- QtScript bindings generator
- v8-juice
- Python/C API Reference Manual
- KDE bindings
- Smoke
- C++ FAQ-lite
- [PDF] How To Write Shared Libraries
One More Thing
What’s presented here came from the many problems solved by all the PySide developers and other kind people, here I’m a mere compiler that decided to write down this knowledge because I felt it could help others (and also our future selves).
